Gannon Hall
Toward Energy Efficient and Transparent AI: A Self-Supervised Learning Approach Using Logical Expressions

Self-supervised machine learning has gained significant attention in recent years as a way to improve the efficiency and performance of artificial intelligence systems. One of the key challenges in self-supervised learning is finding a way to capture the meaning of words and phrases in a way that is understandable to humans.
A new approach to this problem has recently been introduced that uses concise, logical expressions to define the meaning of words. These expressions consist of contextual words such as “black,” “cup,” and “hot” to define other words such as “coffee,” making them easy for humans to understand.
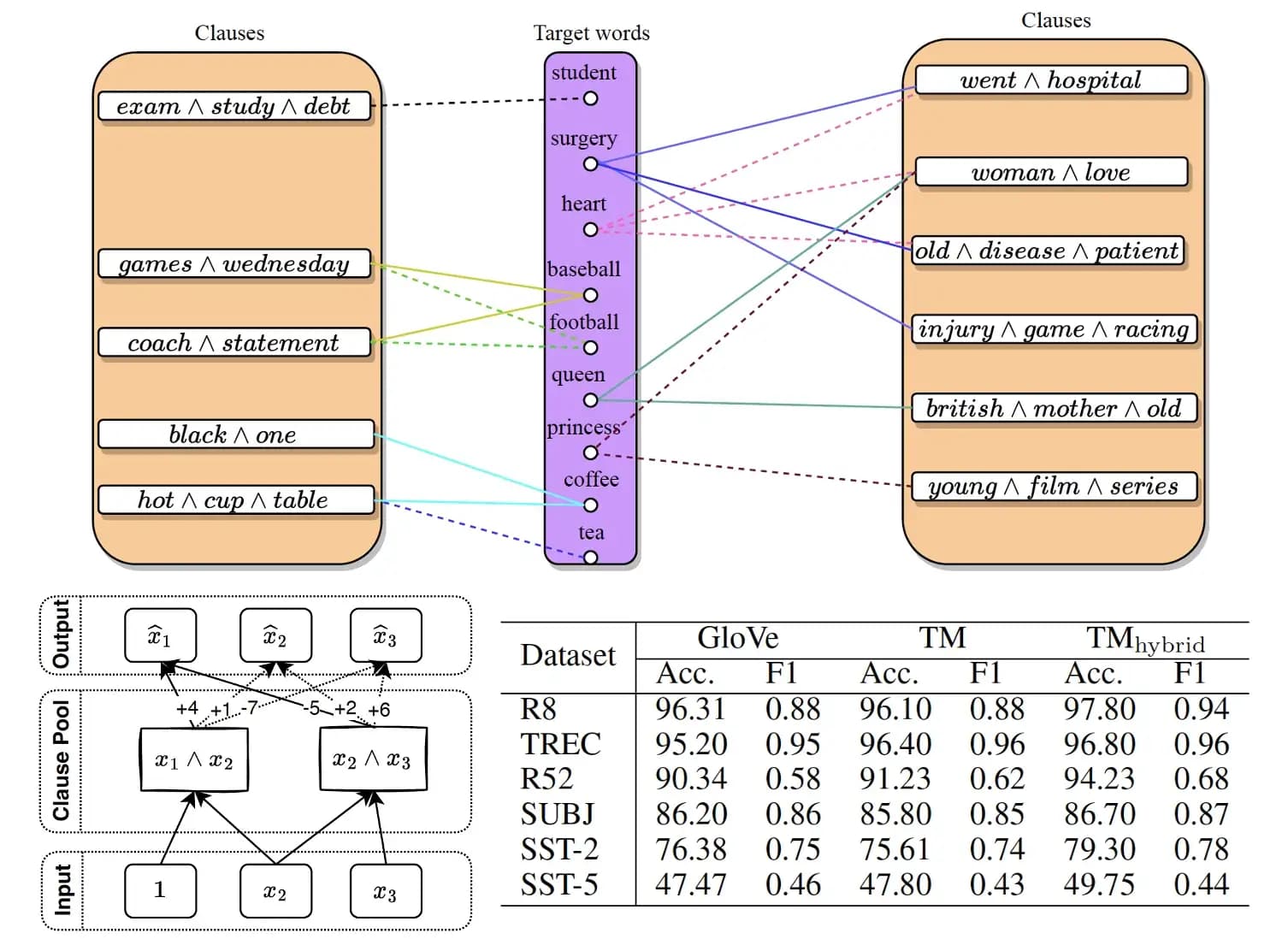
Logical Word Embedding with Tsetlin Machine Autoencoder
The team behind this new approach has found that their logical embeddings perform competitively on a number of intrinsic and extrinsic benchmarks, even matching pre-trained GLoVe embeddings on six downstream classification tasks. This is an exciting development for the field of self-supervised learning, and it opens up the possibility for even more research in the future.
The long-term goal of this research is to provide an energy-efficient and transparent alternative to deep learning. This would be a significant advancement in the field, as deep learning systems can be resource-intensive and difficult for humans to understand.
The paper introducing this new approach as well as an implementation of the Tsetlin Machine Autoencoder and a simple word embedding demo, can be found on GitHub. This is definitely a development worth keeping an eye on, as it has the potential to revolutionize the way we think about self-supervised learning.